Python script to find broken links in word document

I wrote a Python script to find broken links in a word document, the GitHub link is here. If you want to use it you can go to the GitHub page and the instructions are there. Below I will explain how it works and how I came up with this solution.
This program was inspired by helping a friend. The friend has to click on links inside documents one by one to check if they still work. Hearing that, I thought to myself, that sounds like a task that can be automated. Therefore I asked for some sample word documents and started testing the concepts.
In face of this big task, I decided to break the task into a few steps, figuring out a way to do each, and then piece them together.
Step 1: Finding links from texts
If I want to extract some patterns from text, the first thing that pops into my mind is Regular Expression. They are a way to find patterns in texts and are often deemed difficult and feared by developers. Therefore I did what any sane developer would do: search for this problem online and copied the Regex from stack overflow.
The regex is (https?:\/\/\S+), which is pretty easy to understand
| regex | meaning |
| http | http |
| s? | s for zero to one times |
| :// | ://, / stands for an escaped / |
| \S | any non-whitespace character |
| + | the previous token, \S, from zero to infinite times |
Problem 1: the succeeding full-stop is also matched
Let's say I have a sentence that ends in a link, such as http://chit.hashnode.com. If I parse this text in the above regex, the last full-stop (.) will also be included, because it is a non-whitespace character.
the solution is to use another regex, http[s]?:\/\/[^\s]+[^. ], here we have a [^. ], which means: Match a single character not period (.) and not whitespace ( ), so it solves the problem of it catching the trailing period.
Problem 2: having a newline character at the end
The previous regex solves the problem of having a period at the end of the line. But what if there is a newline character after it?
Knowledge dump: What is a newline character
The newline character is the invisible character that tells the text editor to go to the next line. For example, let's say \n is the newline character, I am a line.\nI am another line will become
I am a line.
I am another line
Let's use the website regex101 to test it, when we have A sentence ending in https://google.com., the https://google.com will be correctly captured.
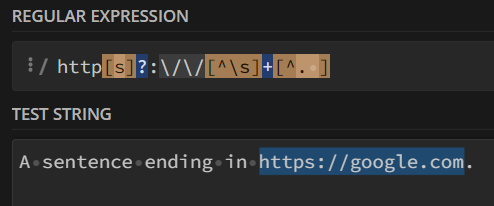
But with a newline character after it, it will be caught as well, since the newline character was not excluded in [^. ].
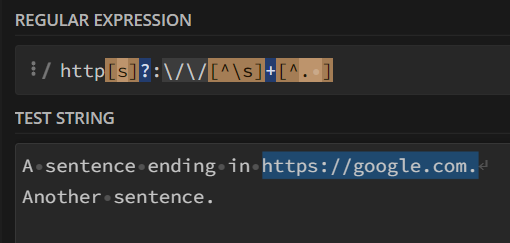
As I am writing this blog post, I figured the solution was to exclude the newline character as well, resulting in the regex http[s]?:\/\/[^\s]+[^. ], but I was not this clear-minded when I was programming, the solution I came up with is to replace all the newline characters with the space bar. Then do the regex matching, which also worked, because there are no longer newline characters.
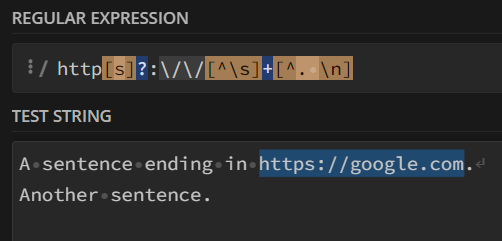
Problem 3: Different types of links
The third problem is with links with no http, our regex only matches links starting with http, but some links start with www, or maybe even no www.
I am sure more clever regexs can accommodate this, but I didn't want to spend too much time at this stage, so I just used a python library to do the work for me. That's the beauty/problem with Python, there are so many libraries that you can just use one, and not care how it is implemented.
from urlextract import URLExtract
urlextracter = URLExtract()
urls = urlextracter.gen_urls(s)
Step 2 Check the links
Now that we have all the URLs from a text extracted, we want to check them.
Problem 4: links without a protocol specified
But remember how some links don't start with HTTP? I need to add an HTTP in front of them, or else the python library request will have a hard time knowing what protocol is required, so I used the following code to achieve that
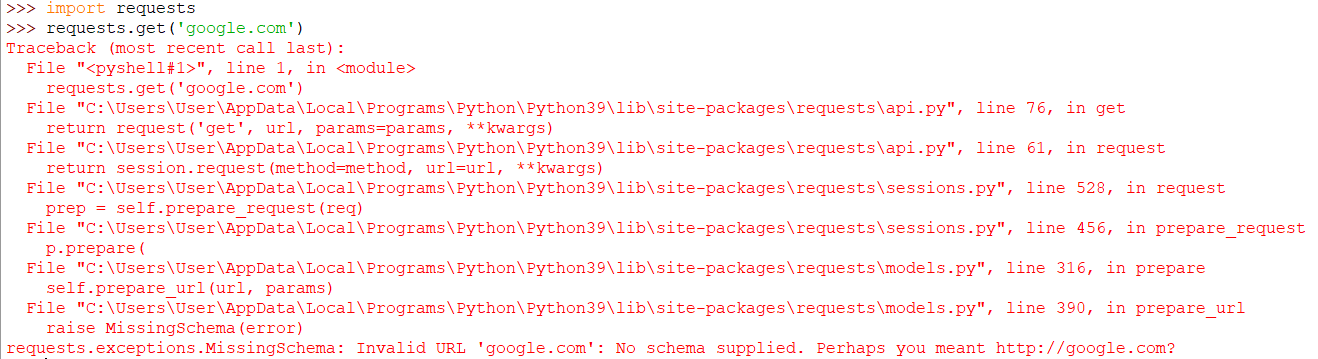
import re
def formaturl(url):
if not re.match('(?:http|ftp|https)://', url):
return 'http://{}'.format(url)
return url
urls = [formaturl(url) for url in urls]
here I try to match the regex (?:http|ftp|https)://, it tests if the URL starts with http/ftp/https, if not, we append http:// in front of it
then we use list comprehension to do it on the entire url list.
Actually checking the link
Now we get to the step of actually checking the link, we do that using the requests library. We wrap the requests.get() inside a try-catch block so that if other issues happen, the program will not crash, it will simply return false. and if the status_code of the response isn't 200, then we return false too, else we return true.
200 means all good, so if the website returns standard content, it will return all good.
def check_link(url):
print(f"checking {url}")
# Try and see if url have inherit problem
try:
response = requests.get(url)
except:
return False
# See if not 200
if not response.status_code == 200:
return False
return True
Step 3: Reading word document text
Now I have a function that extracts URLs, and another to check if the url's website is working. I have to extra the text from a word document.
To do that, I can simply use the save-as function inside word and call it a day. That would save the document in a text format and we can read the text file with the program and get the result.
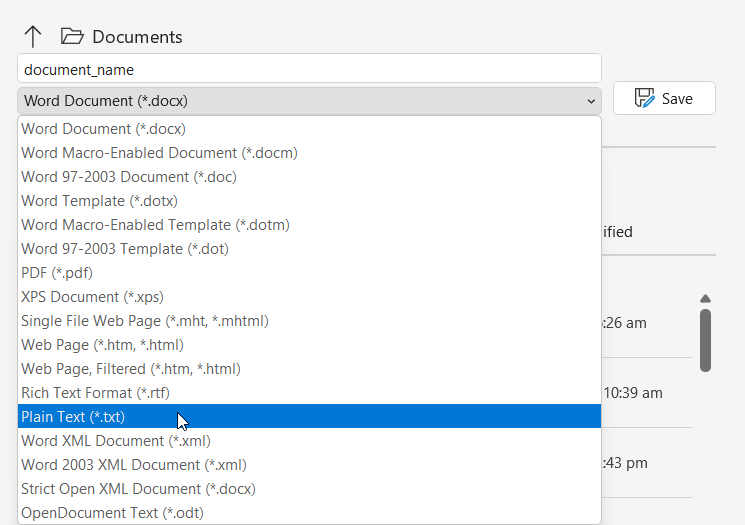
But that would mean the user has to do more, so I was thinking, is it possible to read the word document directly with Python?
The answer is yes because actually, word documents are just zip files. To know if I'm telling you the truth, install 7zip and unzip a word document, and you will see the following result. A word document is just a zip file containing a lot of XML files.
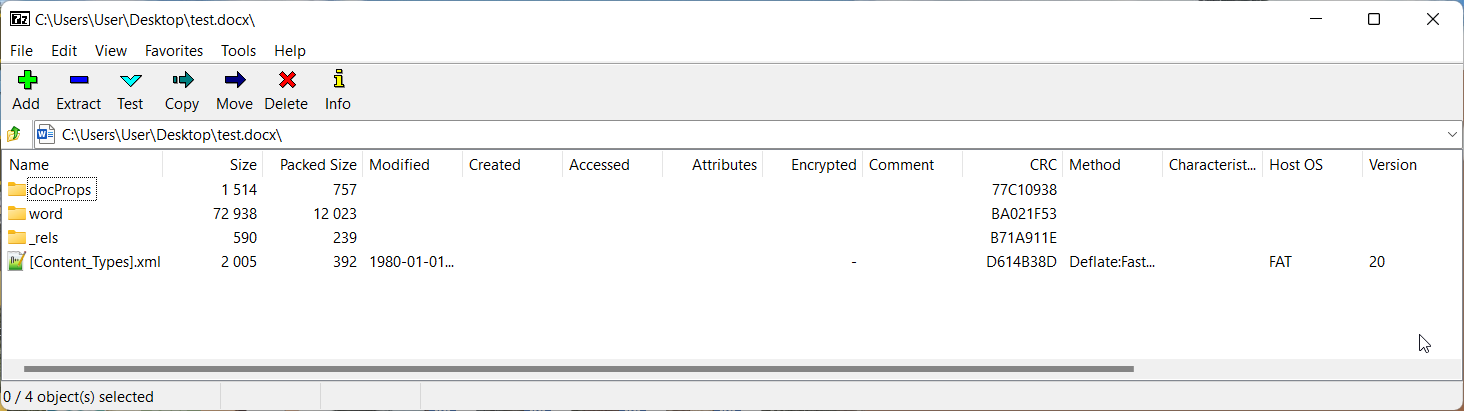
A way to solve this problem is to read the word document as a zip file and find the links inside the XML files. But since I'm using Python, I decided to find if there are any libraries that can do this for me. I found docx, docx2txt, docx2python. After testing them all, the one I decided to use is docx2python, because it extracts the main text, headers, footers, and even footnotes. The syntax is as below:
from docx2python import docx2python
# extract docx content
def get_text_by_docx2python(path):
text = docx2python(path).text
return text
Step 4 Piecing them all together
Now that all parts of the puzzle are here, it is time to implement the main logic, we first extract the text by use_docx2python.get_text_by_docx2python, then urlextracter.gen_urls to get the URLs, after adding http to them, we use check_links.check_link to check the link, and print a helpful message.
Problem: some links show a different result when we request it from the program than when we actually click the site
This is because some sites do not like robots, but since Python requests have the default user agent as python-requests/2.25, the website sees this and forbids the program from getting the result. What we need to do to fix it is to use another user agent, I copied the user agent on my web browser, Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36, then I used response = requests.get(url, headers=HEADERS, stream=True), now the website responds correctly.
Step 5 Doing it asynchronously
Now waiting for the program to do all the things is fine, but it is also too slow. The slowest part is waiting for the websites to be fetched. Since we have to wait for each website to give us the result. This would be faster if we use concurrency, which means doing things at the same time.
Think of it as, burger shop A gives you a burger in 5 minutes, and Boba shop B gives you a boba in 3 minutes. You can get a burger and then a boba in 8 minutes. If you order both at the same time and then collect them when they are ready, you'll only need 5 minutes.
Concurrency code is a bit more complex so I'm not going to explain it here, you can visit RealPython on this topic, they have a great tutorial on this topic.
Step 6 Warp up
At last, I added a code to show a file dialogue to further simplify this for users.
import tkinter as tk
from tkinter import filedialog
file_path = filedialog.askopenfilename()
Conclusion
That's how I did it and I hope you learned something from it.
![Focuster review: My experience as a student in summer [week 3]](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1693222238382%2F06452c01-14a3-423a-9311-83b9d82f6fcc.png&w=3840&q=75)
![Reclaim.AI review: My experience as a student in internship [week 2]](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1692385558997%2F5cd2253e-b50d-4d47-9aad-72807848b1a9.png&w=3840&q=75)
![Motion Review: My experience as a student in internship [week 1]](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1690840123756%2F5bdf844a-d728-430c-8d9b-b88b7b77c726.png&w=3840&q=75)
![Trialling Productivity Tools to Rescue My Time [Week 0]](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1690321356599%2F2f404dbe-3c2a-421b-903c-04d72c8febed.png&w=3840&q=75)
